Series of CXL 3.2 Endpoint Silicon Chips, Customizable to Your Needs
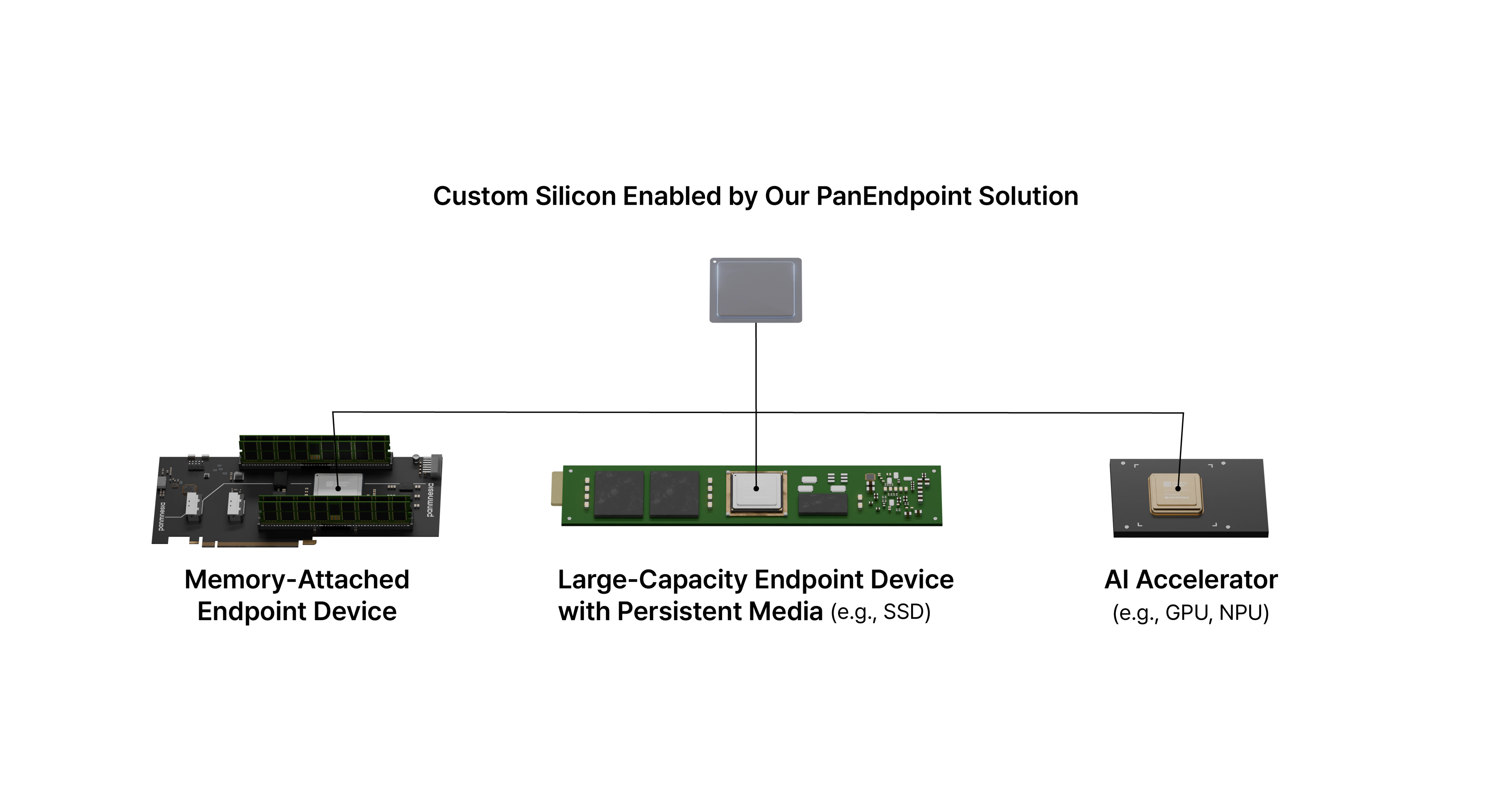
We offer a customizable CXL 3.2 endpoint SoC design service, enabling partners to build their own high-performance hardware tailored to AI, HPC, and cloud workloads. Our PanEndpoint design platform provides a foundation for building CXL 3.2-compliant Type 1/2/3 endpoint chips. It supports direct, low-latency, cache-coherent communication between devices and is fully customizable—allowing you to integrate proprietary logic or modify existing modules to meet your system requirements. Rather than selling off-the-shelf chips, we co-develop silicon solutions with customers to optimize performance and achieve system integration goals. PanEndpoint suits various devices such as memory-attached endpoints, large-capacity storage with persistent media, and AI accelerators. Backed by our IP portfolio and hands-on services—architecture reviews, RTL tuning, and thorough verification—we help partners reach market faster, stay fully standards-compliant, and deliver the performance demanded by next-generation AI, HPC, and cloud infrastructures.
Key Benefits
Hardware-Managed Cache Coherency
Manage cache coherency without software intervention. Built with our Link Acceleration Unit (LAU) IPs, PanEndpoint supports hardware-automated handling of cache coherency features such as back invalidation.
Proven in an End-to-End System
Reduce interoperability risks with end-to-end-proven endpoints. By leveraging our comprehensive portfolio of CXL IPs, all types of CXL EPs have been validated in full-system configurations encompassing CPUs, switches, and endpoints.
Best-In-Class Latency & Power Consumption
Ensure low latency and low power consumption. PanEndpoint employs our Link Controller IP, boasting two-digit nanosecond roundtrip latency. The optimized architecture also offers the lowest power consumption as an endpoint.
Key Features
Our design platform in more detail
Specification | CXL 3.2 Backward compatible with CXL 1.1, 2.0, and PCIe Gen 6 |
Number of lanes | Up to 16 |
Data rate | 64 GT/s |
Bifurcation Support | x4, x8, x16 |
Supported subprotocols | CXL.io, CXL.mem, CXL.cache Unordered IO support Back-invalidation support Direct P2P support |
Supported device types | CXL type 1/2/3 device support Multi-Logical Device (MLD) support Multi-Headed Device (MHD) support Fabric-Attached Memory (FAM) support |
CXL fabric features | Switch cascading (multi-level switching) Tree and non-tree topology supported |
Supported flit format | 68B, 256B, 256B standard, 256B LOpt support |
Power management | Low power state support |
RAS features | Hot-Plug support Data poisoning support Viral support |
Peripherals | UART, I2C, GPIO available |
All specifications are subject to change without notice. Performance may vary based on system configuration and usage patterns.
Real-world Use Cases
AI Training Infrastructure
Accelerate machine learning workloads with high-bandwidth memory expansion and GPU interconnects.
Ideal for large-scale AI training environments requiring massive memory capacity and ultra-low latency communication between accelerators.
Data Center Expansion
Scale your data center infrastructure with flexible CXL device connectivity and memory disaggregation.
Enables dynamic resource allocation and improves overall system efficiency in enterprise environments with growing computational demands.
HPC Cluster Computing
Connect thousands of compute nodes with ultra-low latency for high-performance computing workloads.
Ideal for scientific computing, simulation, and research applications requiring massive parallel processing and fast inter-node communication.